1. Kafka ACK应答机制:消息可靠传递的基础
Kafka通过生产者配置参数acks来控制消息持久化的可靠性级别,这是保证消息不丢失的第一道防线。
1.1 ACK的三种模式
- acks=0:生产者发送消息后立即认为成功,不等待任何确认。性能最高,但可能出现数据丢失。
- acks=1:生产者等待Leader副本写入成功即返回确认。这是默认配置,在Leader故障且副本未同步时可能丢失数据。
- acks=all/-1:生产者等待ISR(In-Sync Replicas)中所有副本都写入成功才返回确认。这是最安全的模式,但延迟最高。
1.2 配置优化建议
`properties
# 生产者配置
delivery.timeout.ms=120000 # 发送超时时间
request.timeout.ms=30000 # 请求超时时间
retries=5 # 重试次数
retry.backoff.ms=100 # 重试间隔`
2. 数据重复问题:根源与挑战
当生产者收到Broker的确认超时或失败时,重试机制可能导致消息重复发送。在分布式系统中,网络分区、节点故障等场景都可能引发"至少一次"语义下的数据重复。
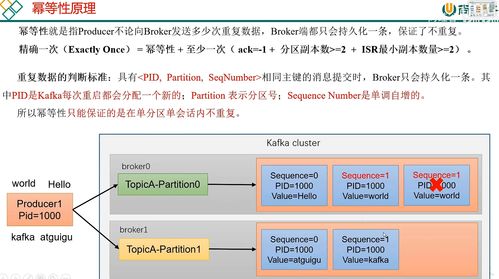
3. 幂等性原理:解决生产者端数据重复
3.1 实现机制
Kafka 0.11+版本引入了生产者幂等性,通过三个关键组件保证单分区内消息不重复:
- Producer ID(PID):每个生产者实例的唯一标识
- Sequence Number(序列号):每个分区内的消息序号
- Epoch(纪元号):防止PID被重复使用
3.2 工作原理
`java
// 启用幂等生产者
Properties props = new Properties();
props.put("enable.idempotence", true);
props.put("acks", "all");
props.put("retries", Integer.MAX_VALUE);
props.put("max.in.flight.requests.per.connection", 5);
// Broker端会检查:
// 1. 同一PID + Partition + Sequence Number的消息
// 2. 序列号连续递增
// 3. 拒绝重复或乱序的消息`
3.3 局限性
- 只能保证单生产者会话内的幂等性
- 只能保证单分区内的幂等性
- Producer重启后PID会变化,无法跨会话保证幂等
4. 事务处理:跨分区与跨会话的可靠性保证
4.1 事务核心概念
- 事务协调器:Broker中的特殊组件,管理事务状态
- 事务日志:
<em>_transaction</em>state主题,持久化事务元数据 - 两阶段提交:准备阶段 + 提交/中止阶段
4.2 事务工作流程
`java
// 生产者事务配置
Properties props = new Properties();
props.put("transactional.id", "my-transactional-id");
props.put("enable.idempotence", true);
// 事务使用示例
KafkaProducer producer = new KafkaProducer(props);
producer.initTransactions();
try {
producer.beginTransaction();
producer.send(new ProducerRecord("topic1", "key1", "value1"));
producer.send(new ProducerRecord("topic2", "key2", "value2"));
producer.commitTransaction();
} catch (Exception e) {
producer.abortTransaction();
throw e;
}`
4.3 事务隔离级别
- read_uncommitted(默认):消费者可以看到未提交的消息
- read_committed:消费者只能看到已提交的消息
5. 在线数据处理与交易处理业务的实践方案
5.1 电商订单场景的完整解决方案
// 订单处理系统的Kafka配置
public class OrderProcessingSystem {
// 生产者配置:保证订单消息的可靠性
private Properties getProducerConfig() {
Properties props = new Properties();
props.put("bootstrap.servers", "kafka1:9092,kafka2:9092");
props.put("transactional.id", "order-producer");
props.put("enable.idempotence", true);
props.put("acks", "all");
props.put("max.in.flight.requests.per.connection", 5);
props.put("retries", 10);
return props;
}
// 处理订单的分布式事务
public void processOrder(Order order) {
try (KafkaProducer producer = new KafkaProducer(getProducerConfig())) {
producer.initTransactions();
producer.beginTransaction();
// 1. 发送订单创建消息
producer.send(new ProducerRecord("orders", order.getId(), order));
// 2. 扣减库存
producer.send(new ProducerRecord("inventory", order.getProductId(),
new InventoryUpdate(order.getProductId(), -order.getQuantity())));
// 3. 生成支付记录
producer.send(new ProducerRecord("payments", order.getId(),
new Payment(order.getId(), order.getAmount())));
producer.commitTransaction();
} catch (Exception e) {
// 事务回滚,所有消息都不会被消费
logger.error("订单处理失败,事务已回滚", e);
throw new OrderProcessingException(e);
}
}
}5.2 消费者端的去重策略
即使生产者保证了精确一次,消费者仍需要自己的去重机制:
// 基于数据库的唯一约束去重
public class DeduplicationConsumer {
@KafkaListener(topics = "orders")
@Transactional
public void consume(Order order) {
// 1. 检查消息是否已处理
if (orderRepository.existsById(order.getId())) {
return; // 已处理,直接返回
}
// 2. 保存订单(数据库唯一约束会防止重复)
orderRepository.save(order);
// 3. 执行业务逻辑
inventoryService.deductStock(order);
paymentService.createPayment(order);
}
}5.3 监控与运维建议
- 监控指标:
- 事务提交/中止率
- 消息重复率
- 端到端延迟
- 生产者重试次数
- 灾难恢复:
- 定期备份
<em>_transaction</em>state主题
- 设置合理的transaction.timeout.ms(默认1分钟)
- 监控事务协调器的负载
6. 性能与可靠性的平衡
6.1 不同场景的配置建议
| 场景 | ACK配置 | 幂等性 | 事务 | 性能影响 |
|------|---------|--------|------|----------|
| 日志收集 | acks=1 | 关闭 | 关闭 | 低 |
| 指标监控 | acks=1 | 开启 | 关闭 | 中低 |
| 订单交易 | acks=all | 开启 | 开启 | 中高 |
| 金融支付 | acks=all | 开启 | 开启 + 消费者去重 | 高 |
6.2 最佳实践
- 分层保障:ACK机制 → 幂等性 → 事务 → 业务层去重
- 合理超时:根据业务容忍度设置delivery.timeout.ms
- 监控告警:建立完整的监控体系
- 测试验证:模拟网络分区、节点故障等异常场景
7. 结论
Kafka通过多层次的可靠性机制,为在线数据处理与交易处理业务提供了完整的解决方案。从基础的ACK应答,到生产者幂等性,再到分布式事务,每个层级都在性能与可靠性之间提供了不同的权衡点。在实际业务中,需要根据具体的业务需求、数据一致性要求和性能指标,选择合适的配置组合,构建既可靠又高效的数据处理管道。
对于关键业务系统,建议采用"事务 + 业务去重"的双重保障策略,在享受Kafka高性能的确保数据的精确一次处理,满足在线交易系统对数据一致性的严格要求。